Matrix Norms#
Matrix norms provide a way to measure the “size” or “magnitude” of a matrix. They are used throughout machine learning and numerical analysis—for example, to quantify approximation error, assess convergence in optimization algorithms, or bound the spectral properties of linear transformations.
Definition#
A matrix norm is a function \( \|\cdot\| : \mathbb{R}^{m \times n} \to \mathbb{R} \) satisfying the following properties for all matrices \( \mathbf{A}, \mathbf{B} \in \mathbb{R}^{m \times n} \) and all scalars \( \alpha \in \mathbb{R} \):
Non-negativity: \( \|\mathbf{A}\| \geq 0 \)
Definiteness: \( \|\mathbf{A}\| = 0 \iff \mathbf{A} = 0 \)
Homogeneity: \( \|\alpha \mathbf{A}\| = |\alpha| \cdot \|\mathbf{A}\| \)
Triangle inequality: \( \|\mathbf{A} + \mathbf{B}\| \leq \|\mathbf{A}\| + \|\mathbf{B}\| \)
These are the minimal axioms for a matrix norm — analogous to vector norms.
Common Matrix Norms#
1. Frobenius Norm#
Defined by:
It treats the matrix as a vector in \( \mathbb{R}^{mn} \).
2. Induced (Operator) Norms#
Given a vector norm \( \|\cdot\| \), the induced matrix norm is:
Examples:
Spectral norm: Induced by the Euclidean norm \( \|\cdot\|_2 \).
Equal to the largest singular value of \( \mathbf{A}. \)
\( \ell_1 \) norm: Maximum absolute column sum.
\( \ell_\infty \) norm: Maximum absolute row sum.
Submultiplicativity#
The submultiplicative property is an additional structure, not a required axiom. Many useful matrix norms (especially induced norms) do satisfy it, but not all matrix norms do.
When a matrix norm satisfies it, we say it is a:
Submultiplicative matrix norm
Induced norms satisfy the submultiplicative property:
For the Frobenius norm:
Norm |
Submultiplicative? |
Notes |
|---|---|---|
Frobenius norm \(|\cdot|_F\) |
✅ Yes |
But not induced from a vector norm |
Induced norms (e.g., spectral) |
✅ Yes |
Always submultiplicative |
Entrywise max norm |
❌ No |
Not submultiplicative in general |
All norms on a finite-dimensional vector space are equivalent (they define the same topology), but may differ in scaling.
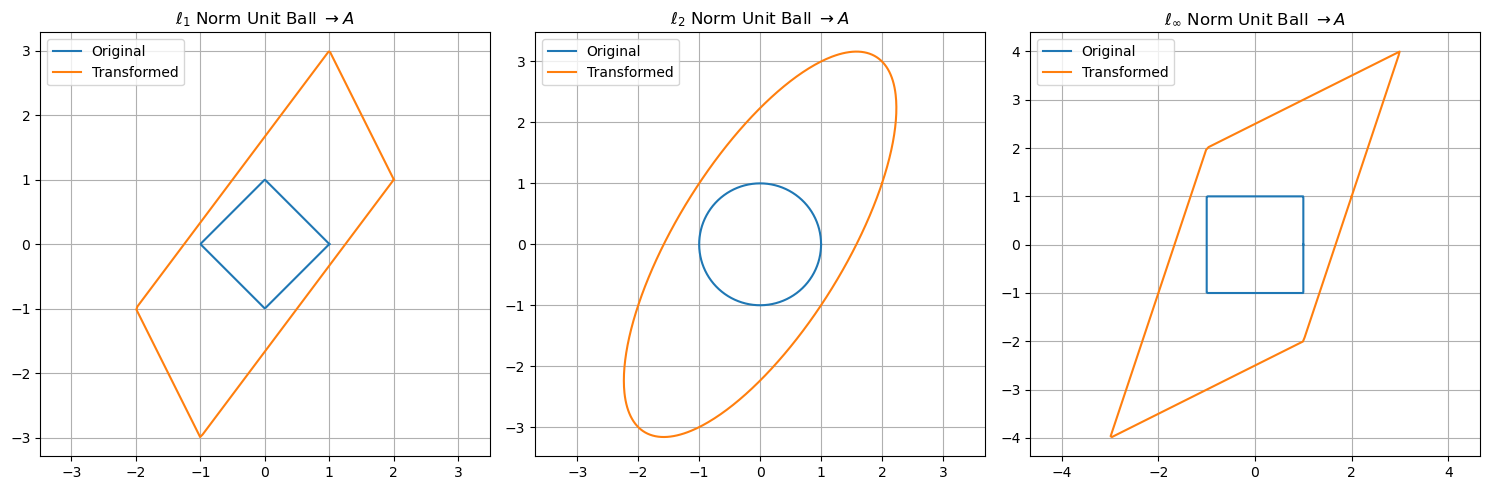
Visual Comparison (2D case)#
In 2D, vector norms induce different geometries:
\( \ell_2 \): circular level sets
\( \ell_1 \): diamond-shaped level sets
\( \ell_\infty \): square level sets
This influences which directions are favored in optimization and which vectors are “small” under a given norm.
Here is a visual comparison of how different induced norms transform unit circles in 2D space under a linear transformation defined by a matrix \( A \):
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Define example matrix A
A = np.array([[2, 1],
[1, 3]])
# Create unit circles in different norms
theta = np.linspace(0, 2 * np.pi, 400)
circle = np.stack([np.cos(theta), np.sin(theta)], axis=1)
# l1 unit ball boundary (diamond)
l1_vectors = []
for v in circle:
norm = np.sum(np.abs(v))
l1_vectors.append(v / norm)
l1_vectors = np.array(l1_vectors)
# l2 unit ball (circle)
l2_vectors = circle
# linf unit ball boundary (square)
linf_vectors = []
for v in circle:
norm = np.max(np.abs(v))
linf_vectors.append(v / norm)
linf_vectors = np.array(linf_vectors)
# Apply matrix A to each set
l1_transformed = l1_vectors @ A.T
l2_transformed = l2_vectors @ A.T
linf_transformed = linf_vectors @ A.T
# Plot
fig, ax = plt.subplots(1, 3, figsize=(15, 5))
# l1 norm effect
ax[0].plot(l1_vectors[:, 0], l1_vectors[:, 1], label='Original')
ax[0].plot(l1_transformed[:, 0], l1_transformed[:, 1], label='Transformed')
ax[0].set_title(r'$\ell_1$ Norm Unit Ball $\rightarrow A$')
ax[0].axis('equal')
ax[0].grid(True)
ax[0].legend()
# l2 norm effect
ax[1].plot(l2_vectors[:, 0], l2_vectors[:, 1], label='Original')
ax[1].plot(l2_transformed[:, 0], l2_transformed[:, 1], label='Transformed')
ax[1].set_title(r'$\ell_2$ Norm Unit Ball $\rightarrow A$')
ax[1].axis('equal')
ax[1].grid(True)
ax[1].legend()
# linf norm effect
ax[2].plot(linf_vectors[:, 0], linf_vectors[:, 1], label='Original')
ax[2].plot(linf_transformed[:, 0], linf_transformed[:, 1], label='Transformed')
ax[2].set_title(r'$\ell_\infty$ Norm Unit Ball $\rightarrow A$')
ax[2].axis('equal')
ax[2].grid(True)
ax[2].legend()
plt.tight_layout()
plt.show()
Let’s give formal definitions and proofs for several commonly used induced matrix norms, also known as operator norms, derived from vector norms.
Let \(\|\cdot\|\) be a vector norm on \(\mathbb{R}^n\), and define the induced matrix norm for \(\mathbf{A} \in \mathbb{R}^{m \times n}\) as:
We’ll now state and prove specific formulas for induced norms when the underlying vector norm is:
\(\ell_1\)
\(\ell_\infty\)
\(\ell_2\) (spectral norm)
1. Induced \(\ell_1\) Norm#
Claim: If \(\|\mathbf{x}\| = \|\mathbf{x}\|_1\), then:
Proof. Let \(\mathbf{A} = [a_{ij}] \in \mathbb{R}^{m \times n}\).
Then by the definition of the induced norm:
Apply the triangle inequality inside the absolute value:
Let us define the column sums:
Then the expression becomes:
since \(\sum_{j=1}^n |x_j| = \|\mathbf{x}\|_1 = 1\), and this is a convex combination of the \(c_j\).
Attainment of the Maximum
Let \(j^* \in \{1, \dots, n\}\) be the index of the column with maximum sum:
Now choose the standard basis vector \(\mathbf{e}_{j^*} \in \mathbb{R}^n\), where:
Then \(\|\mathbf{e}_{j^*}\|_1 = 1\), and:
So the upper bound is achieved, and we conclude:
QED.
2. Induced \(\ell_\infty\) Norm#
Claim: If \(\|\mathbf{x}\| = \|\mathbf{x}\|_\infty\), then:
Proof. Let \(\|\mathbf{x}\|_\infty = 1\).
Then:
Equality is achieved by choosing \(x_j = \operatorname{sign}(a_{ij^*})\) at the row \(i^*\) with largest sum. So:
QED.
3. Induced \(\ell_2\) Norm (Spectral Norm)#
Claim: If \(\|\cdot\| = \|\cdot\|_2\), then:
where \(\sigma_{\max}(\mathbf{A})\) is the largest singular value of \(\mathbf{A}\), and \(\lambda_{\max}\) denotes the largest eigenvalue.
Proof. Let \(\|\mathbf{x}\|_2 = 1\).
Then:
This is the Rayleigh quotient of \(\mathbf{A}^\top \mathbf{A}\), a symmetric PSD matrix.
So:
QED.
Summary Table#
Vector Norm |
Induced Matrix Norm |
|
|---|---|---|
\(\ell_1\) |
Max column sum: |
\(\max_j \sum_i a_{ij}\) |
\(\ell_\infty\) |
Max row sum: |
\(\max_i \sum_j a_{ij}\) |
\(\ell_2\) |
Largest singular value: |
\(\sqrt{\lambda_{\max}(A^\top A)}\) |
Applications in Machine Learning#
In optimization, norms define constraints (e.g., Lasso uses \( \ell_1 \)-norm penalty).
In regularization, norms quantify complexity of parameter matrices (e.g., weight decay with \( \ell_2 \)-norm).
In spectral methods, matrix norms bound approximation error (e.g., spectral norm bounds for generalization).
Collaborative Filtering and Matrix Factorization#
Collaborative filtering is a foundational technique in recommendation systems, where the goal is to predict a user’s preference for items based on observed interactions (such as ratings, clicks, or purchases). The key assumption underlying collaborative filtering is that user preferences and item characteristics lie in a shared low-dimensional latent space. That is, although we observe only sparse user-item interactions, there exists a hidden structure — often of low rank — that explains these patterns.
A common model formalizes this intuition by representing the user-item rating matrix \(R \in \mathbb{R}^{m \times n}\) as the product of two low-rank matrices:
where \(U \in \mathbb{R}^{m \times k}\) encodes latent user features and \(V \in \mathbb{R}^{n \times k}\) encodes latent item features, for some small \(k \ll \min(m, n)\). The model is typically fit by minimizing the squared error over observed entries, together with regularization to prevent overfitting:
where \(\Omega \subset [m] \times [n]\) is the set of observed ratings, and \(\| \cdot \|_F\) is the Frobenius norm. This formulation implicitly assumes that missing ratings are missing at random and that users with similar latent profiles tend to rate items similarly — an assumption that allows the model to generalize from sparse data.
class MatrixFactorization:
def __init__(self, k=2, steps=1000, lam=0.1):
"""
Initializes the matrix factorization model.
Parameters:
- k (int): number of latent features
- steps (int): number of ALS iterations
- lam (float): regularization strength
"""
self.k = k
self.steps = steps
self.lam = lam
self.U = None
self.V = None
def fit(self, R, mask):
"""
Fit the model to the observed rating matrix using ALS.
Parameters:
- R (ndarray): observed rating matrix (with zeros for missing entries)
- mask (ndarray): boolean matrix where True indicates an observed entry
"""
num_users, num_items = R.shape
self.U = np.random.randn(num_users, self.k)
self.V = np.random.randn(num_items, self.k)
for step in range(self.steps):
# Update U
for i in range(num_users):
V_masked = self.V[mask[i, :]]
R_i = R[i, mask[i, :]]
if len(R_i) > 0:
A = V_masked.T @ V_masked + self.lam * np.eye(self.k)
b = V_masked.T @ R_i
self.U[i] = np.linalg.solve(A, b)
# Update V
for j in range(num_items):
U_masked = self.U[mask[:, j]]
R_j = R[mask[:, j], j]
if len(R_j) > 0:
A = U_masked.T @ U_masked + self.lam * np.eye(self.k)
b = U_masked.T @ R_j
self.V[j] = np.linalg.solve(A, b)
def predict(self):
"""
Returns the full reconstructed rating matrix.
"""
return self.U @ self.V.T
def predict_single(self, user_idx, item_idx):
"""
Predict a single rating for a user-item pair.
Parameters:
- user_idx (int): index of the user
- item_idx (int): index of the item
Returns:
- float: predicted rating
"""
return self.U[user_idx] @ self.V[item_idx]
This example demonstrates collaborative filtering via matrix factorization using the Frobenius norm to minimize reconstruction error:
Show code cell source
# Re-import necessary packages after kernel reset
import numpy as np
import matplotlib.pyplot as plt
# Set random seed for reproducibility
np.random.seed(42)
# Generate a low-rank user-item matrix (simulating ratings)
num_users = 10
num_items = 8
rank = 2 # desired low-rank structure
# Latent user and item factors
U_true = np.random.randn(num_users, rank)
V_true = np.random.randn(num_items, rank)
# Generate full rating matrix (low-rank)
R_true = U_true @ V_true.T
# Simulate missing entries by masking some values
mask = np.random.rand(num_users, num_items) < 0.5
R_observed = R_true * mask
model = MatrixFactorization(k=rank, steps=1000, lam=0.1)
model.fit(R_observed, mask)
R_pred = model.predict()
# Plotting the true, observed, and predicted matrices
fig, axs = plt.subplots(1, 3, figsize=(15, 4))
im0 = axs[0].imshow(R_true, cmap='coolwarm', vmin=-5, vmax=5)
axs[0].set_title("True Rating Matrix")
im1 = axs[1].imshow(np.where(mask, R_observed, np.nan), cmap='coolwarm', vmin=-5, vmax=5)
axs[1].set_title("Observed Ratings (with Missing)")
im2 = axs[2].imshow(R_pred, cmap='coolwarm', vmin=-5, vmax=5)
axs[2].set_title("Predicted Ratings via MF")
for ax in axs:
ax.set_xlabel("Items")
ax.set_ylabel("Users")
fig.colorbar(im2, ax=axs, orientation='vertical', fraction=0.02, pad=0.04)
plt.show()
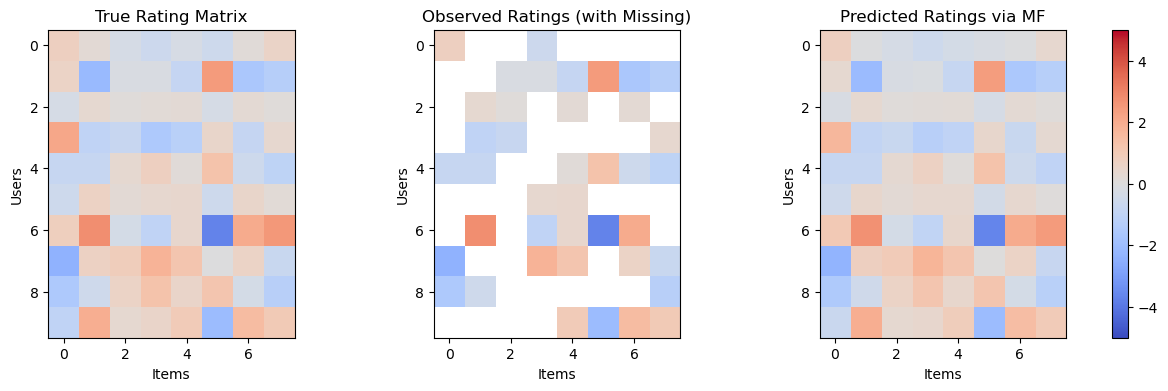
Left panel: The true user-item rating matrix (low-rank structure).
Middle panel: The observed entries, with ~50% missing.
Right panel: The matrix reconstructed via alternating least squares (ALS).